In this paper:
- The problem: you’re making tokens for someone else
- Ribbit Capital’s $41 trillion thesis, and where they stopped short
- What tokens actually are: three layers, one idea
- This is already happening: the signals are everywhere
- Sovereignty Realms: a new framework for who controls what
- Agents are ephemeral, environments are forever: the paradigm shift
- The billboard-to-context-window evolution, and attention is unbounded
- The failed decentralization pattern: internet, crypto, and now AI
- The personal token factory: how it works
- What makes this different, and why incumbents can’t copy it
- The implication, and what comes next
In one sentence: KontextAI lets you turn your files into an AI that works for you — without giving your knowledge to anyone else.
You’ve Been Making Tokens for Someone Else
Every time you paste a paragraph into ChatGPT, every time you upload a PDF to Claude, every time you ask Gemini to summarize your notes — you’re feeding a factory. The factory takes your words, your insights, your hard-won expertise, and turns them into tokens, the atomic units AI uses to process language. Roughly four characters of text each. Thousands per conversation. Millions over time.
But here’s the part no one talks about: that factory isn’t yours.
Your knowledge goes in. Answers come out. The platform captures the value. And you? You get a response. One response. Then the window closes, and everything you provided becomes part of their ecosystem: their usage signal, their benchmark data, their competitive moat. You are a worker in a token factory owned by someone else, paying for the privilege.
This is the defining asymmetry of the AI era: you create the tokens, but you do not own the factory that gives them value.
An important distinction: when you use an AI model, two very different things happen. Inference is the act of using a trained model to generate a response: your query and context enter the model’s context window, the model produces an answer, and the window closes. This is the transaction you’re paying for, and in most API-based deployments, inference data isn’t retained beyond the session. Training is the process of building the model itself, feeding massive datasets into the neural network to shape its weights and capabilities. These are different operations with different data flows.
But the line between them is blurrier than the industry admits. Usage patterns, preference signals, conversation structures: even when your specific text isn’t used for training, the meta-patterns of how you work become product intelligence. Some providers use conversations to improve their models unless you opt out. Some retain your data for safety review. Some make promises about privacy that live in terms of service documents most people never read. The specifics matter less than the pattern: the knowledge flows upstream, and the value stays there. The degree varies; consumer products with default opt-in training are the most direct pipeline, and enterprise API tiers offer stronger guarantees, but the structural incentive remains.
Think about what this means at scale. Your genius, the frameworks you spent a decade developing, the expertise that makes you irreplaceable, dissolves into a collective model that serves everyone. Your knowledge becomes accessible to the world, undifferentiated, unattributed, and uncompensated. Worse: you pay a monthly subscription to access the next version of a model that was trained, in part, on what you taught it for free. Your expertise goes in. Their product comes out. And next quarter, you pay $20 a month to rent back a diluted version of your own intelligence.
You’re not using AI — you’re training someone else’s.
This isn’t a hypothetical dystopia. It’s the current business model of every major AI platform.
Consider the developer who spends six months building a novel workflow with an AI coding assistant. Every session teaches the model something: how to structure projects, how to debug edge cases, how to orchestrate complex systems. The developer owns the code. They own the files. They own the folder structure. But they don’t own what the model learned from watching them work. Next version, those patterns ship as a general capability, available to everyone, attributed to no one. The developer’s methodology became the model’s intelligence. The developer pays the same subscription to access the upgrade that their own ingenuity helped create.
You made the tokens. They keep them.
The Token Factory Thesis
In June 2025, Ribbit Capital, one of the most influential fintech investors in the world and early backers of Robinhood, Coinbase, and Nubank, published one of its periodic letters centered on a single concept: the token factory [1]. They argued that every business on the planet is becoming a token factory, identifying nine distinct types of tokens, from identity tokens to expert tokens. Their thesis was clear: the companies that learn to produce, manage, and deploy tokens at scale will define the next decade of the economy.
This framing carries additional weight because Ribbit has made this kind of call before, early and correctly. In 2013, they published what became known as their “Bitcoin Letter,” arguing for the long-term significance of Bitcoin when it was still widely dismissed as a fringe experiment, trading at roughly $100–$1,000 per coin. It’s one thing to recognize a paradigm once it’s obvious. It’s another to identify it a decade early.
The token factory thesis should be read in that context: not as commentary, but as pattern recognition from an investor that has repeatedly identified where value accrues before the rest of the market catches up.
We owe a debt to Ribbit for this framing. Their thesis gave language to something we’d been building toward but hadn’t yet named. The token factory is the right metaphor. The nine token types are the right taxonomy. The $41 trillion opportunity is, if anything, conservative [1].
Ribbit goes further than taxonomy. They describe tokens compounding through loops, flywheels where each token generated creates the conditions for the next [1]. Identity tokens enable credential tokens. Credential tokens unlock expert tokens. Expert tokens generate attention tokens. The loop accelerates. KontextAI’s memory pipeline is exactly this kind of flywheel at the personal level: every conversation enriches the knowledge base, which improves future responses, which generates richer conversations. The tokens compound.
Where we build on their thesis is in the direction of the telescope.
Ribbit sees token factories as institutional infrastructure: banks tokenizing identity, enterprises tokenizing workflow, platforms tokenizing content [1]. That’s right, and it’s important. But there’s a factory that’s older, more numerous, and arguably more valuable than any institution’s.
The most valuable token factory isn’t a company. It’s a person.
What We Mean by “Token”
Before we go further, let’s be precise about a word that carries too much baggage.
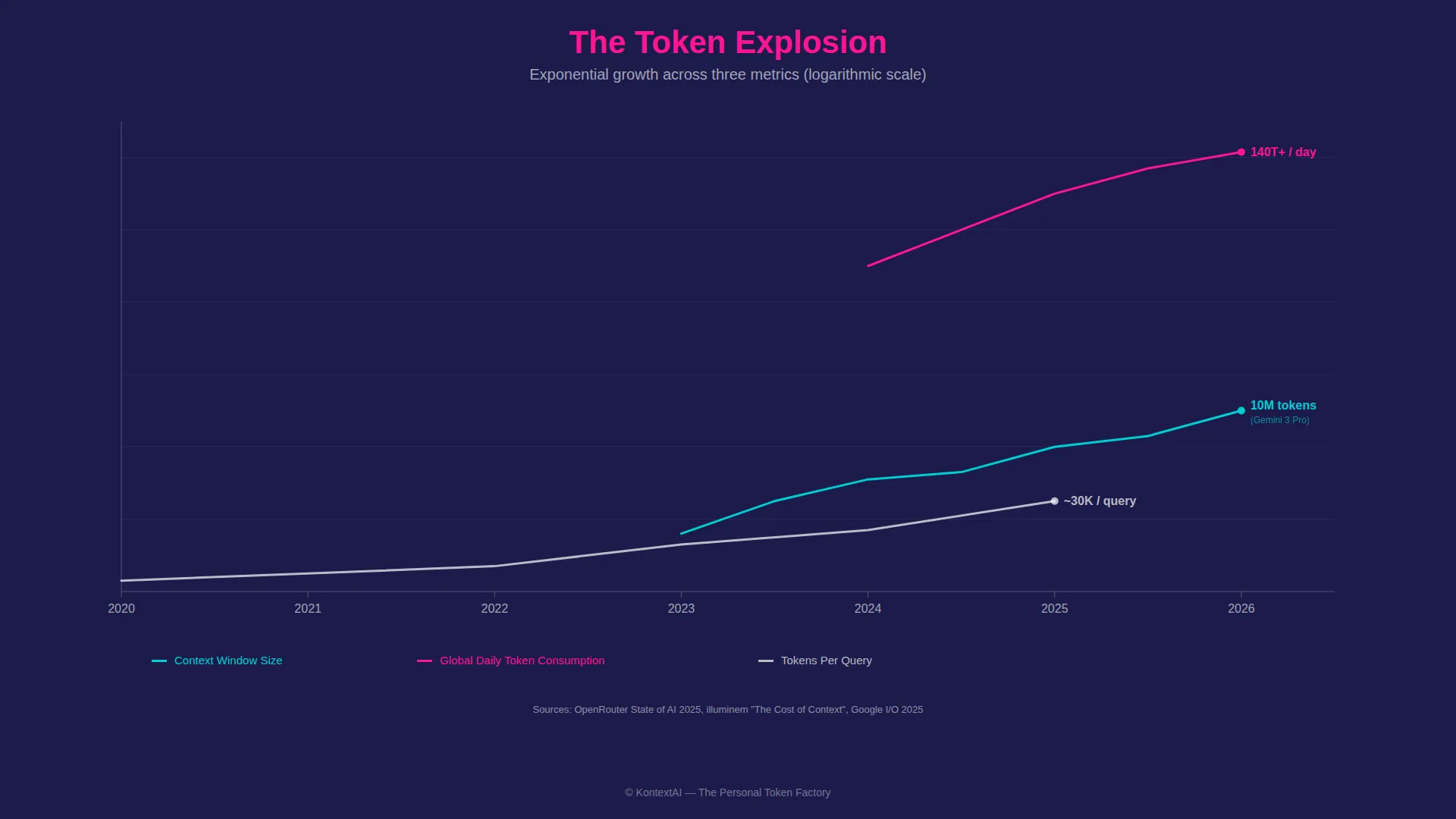
When most people hear “token” in the context of AI, they think of the mechanical definition: approximately four characters of text, the atomic unit a language model processes. A sentence becomes a sequence of tokens. A document becomes thousands. The context window (the AI’s working memory) is measured in tokens. In early 2023, the standard context window was 4,000 to 8,000 tokens. By early 2024, it reached 128,000. Today, leading models process 1 million to 2 million tokens in a single context window, with 10 million now live in Gemini 3 Pro, enough to hold the equivalent of approximately 30 full-length books in a single session. The scale of consumption is staggering: China’s daily AI token usage alone went from approximately 100 billion in early 2024 to over 140 trillion by March 2026, a more than thousand-fold increase in two years [2]. Google reported processing 980 trillion tokens per month by mid-2025, up from approximately 480 trillion tokens per month just three months earlier, at I/O in May 2025 [3]. The rate of growth may be more significant than the absolute number: a doubling in a single quarter suggests the ceiling is nowhere in sight. Tokens per query grew from roughly 200 in 2020 to tens of thousands by 2025, as AI evolved from simple Q&A into multi-step reasoning, tool use, and self-correction, with chain-of-thought and planning overhead often consuming far more tokens than the visible response.
When crypto enthusiasts hear “token,” they think of digital ownership: a blockchain-verified claim on an asset, a right, or a membership. You own it. You can transfer it. No intermediary controls it.
When Ribbit Capital says “token,” they mean something broader: nine distinct types (identity, expert, context, credential, memory, asset, payment, access, and attention) that together represent the full taxonomy of value that flows through the modern economy [1].
These are not competing definitions. They are layers of the same idea: representing value in a form machines can process. This is a metaphorical bridge, not a technical equivalence. An LLM token and a crypto token share a name, not a mechanism. But the convergence is real: all three represent the same underlying shift: encoding human value in forms that digital systems can store, search, transfer, and act on. An LLM token is the mechanical layer, how knowledge gets encoded. A crypto token is the ownership layer, the entity that controls the asset. Ribbit’s taxonomy is the economic layer, what kinds of value exist and how they move [1].
When we say “token factory,” we mean all three. Your expertise is encoded as LLM tokens. Your ownership of that expertise should be as absolute as a crypto wallet. And the economic value of your tokens (identity, expert, context, credential) should flow to you, not to the platform that happened to process them.
But before we can talk about what a personal token factory looks like, we need to talk about the concept that makes it matter: sovereignty. Not sovereignty as a buzzword. Sovereignty as architecture.
This Is Already Happening
The shift to personal token factories is not theoretical. It is already happening, just without the infrastructure to support it.
Everywhere you look, people are solving the same problem in fragmented ways:
- Developers are exporting conversations from AI coding assistants because they realize their best work is trapped in sessions that disappear.
- Knowledge workers are building second brains in Notion, Obsidian, and Google Drive, not because those tools are sufficient but because they are the only place their thinking persists.
- Researchers are hoarding PDFs, hundreds, sometimes thousands, because the cost of re-finding knowledge is lower than the cost of losing it.
- Teams are building internal RAG pipelines, ad hoc, fragile, and constantly breaking, to make their own documents queryable.
- Enterprises are spending millions on AI knowledge management systems that still cannot reliably retrieve their own institutional memory.
These are not edge cases. These are signals. They all point to the same underlying truth: people already understand that their knowledge is valuable, but they don’t have a system that makes it computable without giving it away.
Right now, the only options are to paste knowledge into a model and lose control, or to store knowledge in files and lose usability. So users do both, storing privately and computing externally. This behavior is the clearest signal of a missing layer in the stack.
There is a deeper reason this shift cannot be avoided. In a system where AI outcomes are determined by context, but users do not control that context, value will always concentrate upstream. That system is inherently unstable. The more people rely on AI for decisions, the more they will demand control over the knowledge underlying those decisions. This is not a preference shift. It is a structural one. A context-driven economy without context ownership creates a permanent imbalance between value creation and value capture. And systems with that imbalance do not persist. They get replaced.
Sovereignty Realms
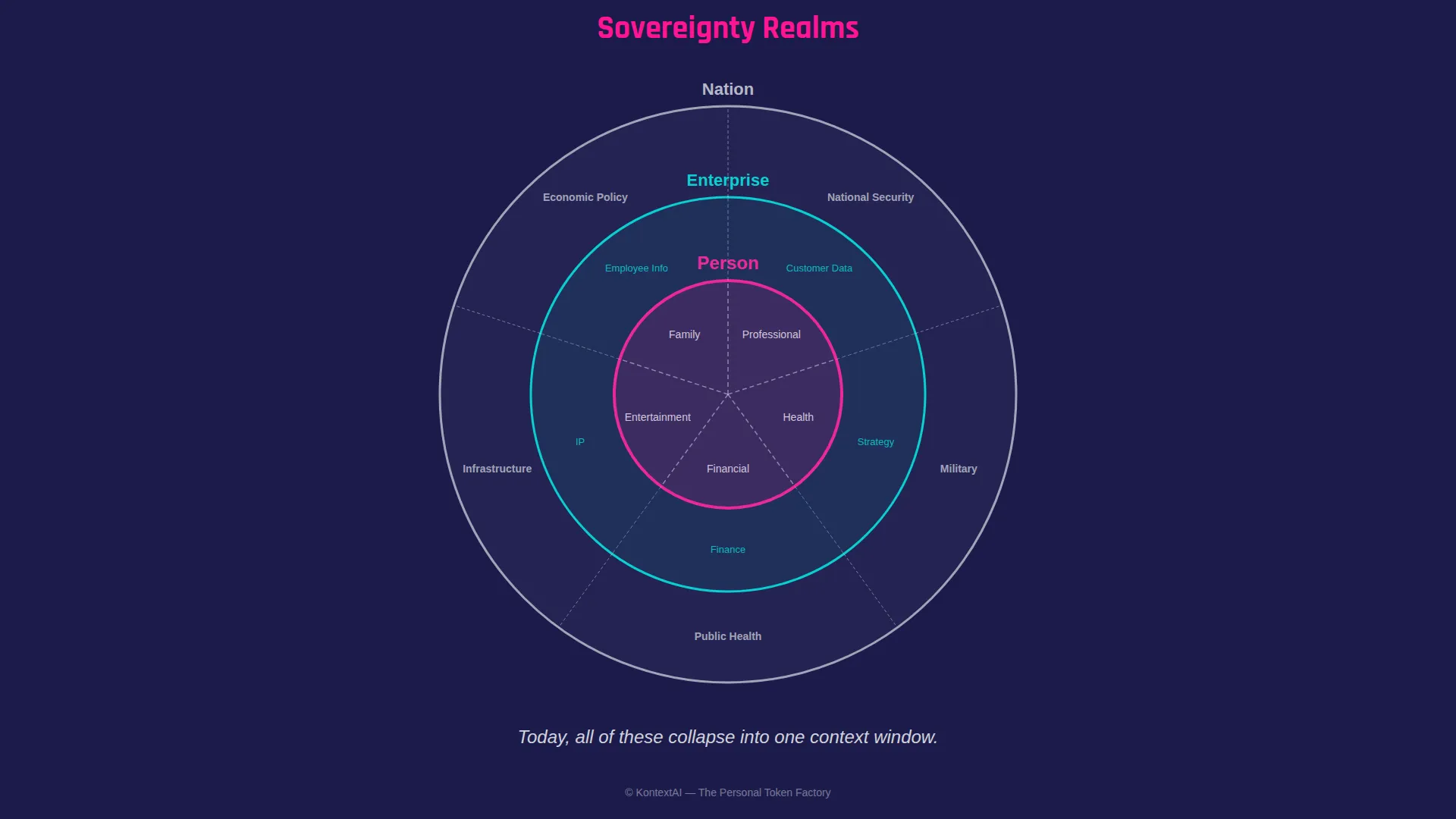
Sovereignty isn’t one thing. It’s nested domains of control. Every entity (every nation, every company, every person) operates across multiple realms, each with different sensitivity, different rules, different stakes.
A country has realms: national security, cultural heritage, public health, economic data, and citizens’ personal information. Violate the boundary of one, and you may trigger an international incident. Violate another, and you trigger a regulatory investigation.
An enterprise has realms: customer data, competitive strategy, compliance and regulatory obligations, intellectual property, and employee information. The engineering team’s code review discussions live in a different realm than the board’s M&A deliberations, even though both belong to the same company.
A person has realms too, and this is where the current AI landscape fails most profoundly. Your professional expertise. Your personal health records. Your financial situation. Your creative work. Your private life. These are distinct domains with distinct sensitivity levels, distinct sharing rules, and distinct consequences if boundaries are violated.
Today, all of these realms get dumped into the same context window.
When you paste your business strategy into ChatGPT and then ask about your child’s homework, both realms are in the same system, under the same terms of service, governed by the same training policy. No boundary. No isolation. No sovereignty. When a consultant uploads a client’s financial model and then asks a personal health question in the same session, two radically different realms, one governed by professional confidentiality agreements, the other by HIPAA expectations, are commingled in a system designed to treat all input identically.
Jensen Huang, CEO of NVIDIA, put it in terms of national sovereignty: “Every country needs to own the production of its own intelligence” [4]. He’s right, and the principle scales down. Every enterprise needs to own its intelligence. Every person needs to own theirs. And within each entity, different realms of intelligence require different boundaries.
HP’s Chief Commercial Officer, David McQuarrie, captured the consumer reality: “In a world where sovereign data retention matters, people want to know that if they input data to a model, the model won’t train on their data” [5]. That’s the minimum. What people actually need, whether they’ve articulated it yet or not, is realm-level control. Not just “don’t train on my data” but “my health data and my work data should never exist in the same queryable space.”
Alan Kay, the computer scientist who helped invent the personal computer, said that “point of view is worth 80 IQ points” [6]. We’d paraphrase that for 2026: context is worth 80 IQ points, and the person who owns the context owns the IQ. But here’s the nuance Kay’s formulation implies: the wrong context in the wrong place doesn’t add IQ points. It creates liability.
McKinsey estimates that 30-40% of global AI spending, between $500 billion and $600 billion by 2030, will be influenced by data sovereignty requirements [7]. The EU AI Act, effective August 2026, introduces compliance obligations that scale with risk level, with penalties reaching 35 million euros or 7% of global revenue [8]. These regulations exist precisely because sovereignty realms are real, consequential, and currently unprotected.
But the regulatory approach treats sovereignty as a compliance checkbox. What’s needed is sovereignty as architecture: systems designed from the ground up to respect realm boundaries, not systems that bolt on privacy controls after the fact.
To make this concrete, here is what sovereignty realm enforcement looks like architecturally:
realms:
professional:
sources: [/kb/client_frameworks/**, /kb/case_studies/**]
tools: [pgvector_search, spreadsheet_analyzer]
cross_realm_access: []
health:
sources: [/kb/medical_records/**, /kb/prescriptions/**]
tools: [medical_reference]
cross_realm_access: []
financial:
sources: [/kb/tax_returns/**, /kb/investments/**]
tools: [financial_calculator]
cross_realm_access: [professional/read_only]By defining realms structurally, the agent’s reasoning loop physically cannot pull content from an unauthorized namespace. In a naive setup, a single “life assistant” agent might summarize both a founder’s fundraising deck and their therapy notes from the same vector store. In KontextAI, those reside in different agents, and cross-agent retrieval is architecturally prevented, not governed by policy but by design. The isolation happens at the data-retrieval layer before the model ever sees the prompt.
To our knowledge, no existing framework in academic literature, industry analysis, or product marketing proposes isolating different categories of personal knowledge within AI systems as distinct governance domains. Every major treatment of AI data sovereignty, from McKinsey to the EU AI Act, frames the issue at the national or enterprise level. Applying sovereignty as nested personal realms is, as far as we can determine, a new idea. We call it Sovereignty Realms.
KontextAI’s position: sovereignty extends to the individual and their sub-realms. Not as a policy. As a design principle.
To be precise about what sovereignty means architecturally: your knowledge base exists in per-user isolated storage. Retrieval is scoped; queries in one realm cannot pull content from another. Access controls enforce realm boundaries. This is not cryptographic isolation. The same foundation models process queries across all users, and embeddings share a mathematical space even when stored separately. The sovereignty boundary operates at the data and retrieval layers, not at the model layer. This is the correct architectural boundary: sovereignty lives at the data and retrieval layer, not the model. Model-level isolation would mean running separate models per user, which is neither economically viable nor technically necessary for the privacy guarantees most users need.
Agents Are Ephemeral. Environments Are Forever.
For four decades, the AI industry has been building agents. Expert systems in the 1980s. Chatbots in the 2010s. Multi-agent pipelines in the 2020s (LangChain, LangGraph, Semantic Kernel, AutoGen). Each generation brought more sophistication. Each generation shared the same assumption: an agent is a piece of software you build, deploy, and maintain. A researcher agent. A legal agent. A coding agent. Each one a capital investment in engineering.
That assumption is breaking down.
Jake Van Clief, a developer who spent three years building multi-agent pipelines across every major framework, put it bluntly: “Everyone’s trying to build a perfect agent. That’s a waste of time. If you can capture the environment, the workflows, the processes, the details, then one single foundation model can live inside that environment and create its own agents on the fly that do the task better than your hand-built agent ever would” [9]. His arXiv paper states it even more precisely: “The model’s capabilities do not change between stages. What changes is the information it has available when generating output” [9]. The model is constant. The environment is the variable.
The reality is a spectrum, not a binary. Production agent systems still require orchestration, authentication, tool integration, and persistent memory that outlives any single session. Claude Code itself maintains a MEMORY.md file that persists across conversations. OpenClaw agents run as long-lived services on dedicated infrastructure. The ephemeral quality is in the agent’s decision-making context, the context window that assembles at query time and dissolves after, not in the entire system. The environment persists. The orchestration persists. The memory persists. What’s ephemeral is the specific combination of context, instructions, and retrieved knowledge that constitutes the agent’s “mind” for the duration of a single task.
But the direction is clear. Anthropic’s engineering team describes their own architecture in these terms: “Skills are reusable, filesystem-based resources that provide Claude with domain-specific expertise: workflows, context, and best practices that transform general-purpose agents into specialists” [10]. The framework creators themselves are building for environment-defined agents.
This is exactly what’s happening. Claude Code doesn’t ship with pre-built agents. It reads markdown files (skill definitions, context documents, project instructions) and assembles an agent at runtime from the environment it finds itself in. The agent exists for the duration of the task and then disappears. The .md file persists. The agent doesn’t. OpenClaw works the same way. So does Codex. The pattern is universal: the environment is the product, the agent is ephemeral.
This changes everything about sovereignty.
If agents were permanent software, protecting them would be a standard intellectual property problem. You built something, you register it, you defend it. But if agents are ephemeral, born from an environment and dissolved after the task, then the environment is the only thing that persists. Your files. Your knowledge. Your methodology. Your sovereignty realm. That IS the asset. The agent was just a momentary expression of it.
The model is the tool. The context is the asset. Ownership of the asset determines the outcome.
This is why Big AI’s model is so structurally dangerous. They don’t need to steal your agent — it doesn’t exist long enough to steal. They need to absorb your environment into their base model through training. Once your knowledge is in the model, they can spin up ephemeral agents from it infinitely, without you, without attribution, without compensation. Sovereignty isn’t about protecting an agent. It’s about protecting the environment that agents are born from.
Some of those environments need strict isolation. Your health realm should never bleed into your professional realm. A question about a medical diagnosis should never surface in a work query, no matter how sophisticated the AI. That’s not a feature gap. That’s a sovereignty violation.
But some environments should deliberately collaborate. Your financial realm and your tax realm operate in adjacent spaces where isolation would make both less useful. The boundary between them should be permeable by design, not by accident.
We’re living this problem with our own agent fleet.
KontextAI runs on a system called OpenClaw, our internal AI agent platform for business operations. Our agents have explicit realm boundaries defined by function:
- The operations function can see business documents (financial projections, operational plans, vendor contracts) but cannot access source code or engineering decisions. Business realm. Not engineering realm.
- The support function can see public documentation and FAQ databases but cannot access internal business documents or financial data. Public-facing realm. Not internal realm.
- The infrastructure function has access to server configurations and deployment logs but cannot access customer data or business financials. Infrastructure realm. Not data realm.
- The communications function has brand voice guidelines and approved messaging but cannot access financial data or internal strategy. Brand realm. Not operational realm.
These aren’t arbitrary restrictions. They’re sovereignty realm boundaries applied to agent environments. The operations function doesn’t need source code. The support function doesn’t need financial projections. Each function defines an environment with explicit boundaries, and when an agent is invoked within that environment, it inherits those boundaries automatically. The agent is ephemeral. The boundaries are permanent.
In mid-March 2026 at GTC, Jensen Huang stood in front of every enterprise CEO in the room and asked a single question: “What’s your OpenClaw strategy?” [11]. He compared it to the moments when every company needed a Linux strategy, a web strategy, a cloud-native strategy. He called OpenClaw “the new Linux” and “definitely the next ChatGPT” [11][12]. NVIDIA announced NemoClaw, enterprise-grade OpenClaw with security and data sovereignty built in. The message was unambiguous: the agentic future isn’t coming. It’s here. And it runs on environments, not hand-built software agents.
KontextAI doesn’t just have an OpenClaw strategy. We have OpenClaw employees. Our operations function runs on OpenClaw around the clock, managing business planning, financial analysis, vendor research, and internal documentation. Not as a demonstration. As actual staff. The agent operates within defined sovereignty realm boundaries, accessing business documents but never source code, producing real deliverables that drive real decisions. When the agent needs to execute a task, it assembles a context window from its environment (the files, the memory, the realm configuration), does the work, and the context dissolves. The environment persists. The deliverables persist. The agent was ephemeral. The value was not. The question Jensen posed to CEOs is the same question we pose to every professional, every enterprise, every institution with knowledge worth protecting: who owns the environment from which your agents are born?
Files and folders are the new agents. The environment is the product. And the person — or enterprise, or nation — who controls the environment controls everything the agents that emerge from it can do.
The Billboard-to-Context-Window Evolution
To understand why sovereignty realms matter in practice, look at what you’re actually buying when you interact with AI.
For a century, the economics of attention were simple: you paid to occupy space in a human’s field of vision. A billboard on a highway. A banner on a webpage. A sponsored result in a search engine. The medium changed, but the model never did. You were renting someone else’s real estate, hoping the right person would look at it at the right time.
| Era | Medium | What You Were Buying |
|---|---|---|
| 1900-2000 | Billboards, TV, print | Space in a human’s visual field |
| 2000-2023 | Banner ads, SEO, paid search | Space in a human’s search results |
| 2023-present | AI agents, context windows | Space in an AI’s working memory |
The third row is where everything changes.
In the age of AI agents, the most valuable real estate isn’t a screen or a search result — it’s the context window, the finite space inside an AI’s working memory where your knowledge either exists or doesn’t. At 10 million tokens, that window can hold approximately 30 full-length books, a very large billboard indeed. If your expertise is in that window when a question gets asked, you’re the answer. If it isn’t, you’re invisible.
The critical variable is retrieval quality, the system’s intelligence that decides which knowledge makes it into the window. A large context window with poor retrieval is an empty billboard. The indexing pipeline, the embedding quality, the chunking strategy, the reranking logic: these are the mechanisms that determine whether your expertise shows up when it matters.
This isn’t a metaphor. It’s how retrieval-augmented generation (RAG) works, a technique where an AI searches a knowledge base, pulls the most relevant passages into its active memory, and generates a response grounded in that content. The knowledge that makes it into the window shapes the answer. Everything else might as well not exist.
There’s a reason the foundational AI paper of the last decade is titled “Attention Is All You Need.” The 2017 transformer architecture replaced recurrent processing with self-attention, proving that how a model allocates attention across its input determines the quality of its output. Subsequent scaling research showed that model size matters too. But the foundational insight holds: attention is the mechanism, and the context window is where attention operates. What’s in the window shapes what comes out. Ribbit Capital closed their token factory thesis with this same reference, and they were right to [1].
The numbers behind this shift are staggering. ChatGPT alone now has more than 800 million weekly active users [13]. Hyperscalers are spending $399 billion on AI infrastructure in 2025, a 68% increase year over year [14]. The RAG market is valued at $3.3 billion in 2026 and projected to reach $9.86 billion by 2030 [15]. a16z’s “Big Ideas 2026” report identified unstructured, multimodal data as enterprises’ biggest bottleneck, and the same is true for individuals [16].
The context window is where sovereignty matters most. It’s the place where your knowledge is either yours or someone else’s. And right now, for 800 million people a week [13], it’s someone else’s.
Consider the scale of what’s coming. You have two eyes. Your attention is finite: one screen, one search result, one conversation at a time. But in an agentic world, the number of context windows operating on your behalf isn’t constrained by biology. It’s constrained by nothing at all. Today’s agentic frameworks show us that agents aren’t permanent residents; they’re ephemeral. A prompt file is called at runtime, a context window is spun up for the duration of a task, and torn down when it’s done. An enterprise doesn’t have “500 agents.” It can invoke thousands of agent instances per hour, each assembling a context window, making a decision, and disappearing. A nation-state’s intelligence apparatus doesn’t run on a fixed fleet; it runs on a continuous stream of ephemeral agent processes, each one a billboard slot that exists for milliseconds.
We may not even be thinking about this correctly yet. The number isn’t dozens or thousands. In a world where agents are as disposable as function calls, the total surface area of machine attention is effectively unbounded. The context window is ephemeral. The outcomes are permanent, and they impact the real world. A medical agent’s context window exists for seconds, but the treatment recommendation it produces shapes a patient’s life. A financial agent’s context window vanishes after the query, but the investment decision it informs moves real money. The question of what knowledge occupies those windows, whose expertise gets retrieved, whose methodology shapes the answer, will matter far more than what occupies any billboard a human might glance at.
We’ll return to this in Part 2.
The Failed Decentralization Pattern
There’s a historical pattern here that’s worth naming explicitly, because Big AI is following it beat for beat.
The promise of the internet was decentralization. Anyone can publish. Anyone can build. Power flows to the edges. Tim Berners-Lee’s original vision was a web where every node was both a consumer and a producer, a distributed network with no center.
Instead, the internet has been centralized into five companies. Google captured search. Facebook captured social. Amazon captured commerce. Apple captured the device. Microsoft captured the enterprise. The infrastructure was decentralized. The value was not. The edges produced the content; the center captured the economics.
Big AI is following the same trajectory. The infrastructure is ostensibly open: open-source models, open APIs, open research papers. But the value is centralizing fast. A handful of companies are building the platforms where everyone else’s knowledge flows in, and their economics flow out. Sound familiar?
Crypto was the first serious attempt to re-decentralize. And it worked. You actually own your wallet. You actually hold your keys. You can transact without permission from a central authority. The blockchain proved a fundamental point: digital sovereignty is possible when the architecture is designed for it. That idea, that ownership can be embedded in the infrastructure itself rather than bolted on as a feature, is one of the most important ideas of the last two decades.
The fight against centralized finance is now playing out in AI. And the stakes are arguably higher. Big Finance centralized your money. Big AI is centralizing your knowledge: every insight, every methodology, every hard-won framework you’ve spent years building. The parallel is exact. The major AI platforms are becoming the financial institutions of the intelligence era. The infrastructure feels open. The models feel accessible. But the value is centralizing at the same speed and for the same structural reasons.
Crypto showed us the fight is worth having. Now it needs to be fought across every sovereignty realm, not just financial but intellectual — knowledge sovereignty.
We’ve seen this pattern break before. In 1984, Apple ran an ad during the Super Bowl depicting IBM as Big Brother, a monolithic system that controlled the computing experience for everyone. The Macintosh was the hammer that shattered the screen. Personal computing didn’t win by building a better mainframe. It won by giving individuals ownership of their compute. The machine was yours. The files were yours. The applications ran on your hardware, not on IBM’s time-sharing system.
The mainframe era of AI is ending. The major AI platforms (ChatGPT, Claude, Gemini, and the rest) are the time-sharing terminals of 2026. You log in. You use someone else’s infrastructure. Your work product lives on their servers under their terms. And like the mainframe era before it, this model is already showing cracks. The dominant chatbot’s market share fell from 69.1% in January 2025 to 45.3% by Q1 2026 [17], and new entrants are proving the market is fragmenting fast. Grok surged from 1.6% to 15.2% in under a year [17], demonstrating that a brand-new competitor can take significant share when the incumbents feel interchangeable. The products, as one analysis put it, increasingly feel “designed to convert rather than to help” [17]. Industry analysts estimate only a small fraction of users pay, yet those paying users generate the majority of platform revenue, funding a system where the vast majority are giving their knowledge away for free.
This is not sustainable. Not for the platforms, and certainly not for the people feeding them.
KontextAI applies sovereignty to knowledge, the asset that matters most in the age of AI. The architecture borrows crypto’s core insight (ownership embedded in infrastructure) and Apple’s original promise (the machine is yours) without requiring the complexity of either. You don’t need a blockchain, a wallet, or a seed phrase. You don’t need to build your own hardware. You need a file and an upload button.
The Personal Token Factory
Now that we’ve established what tokens are, what sovereignty realms protect, and why environments outlast agents, here’s what it looks like when you build the factory.
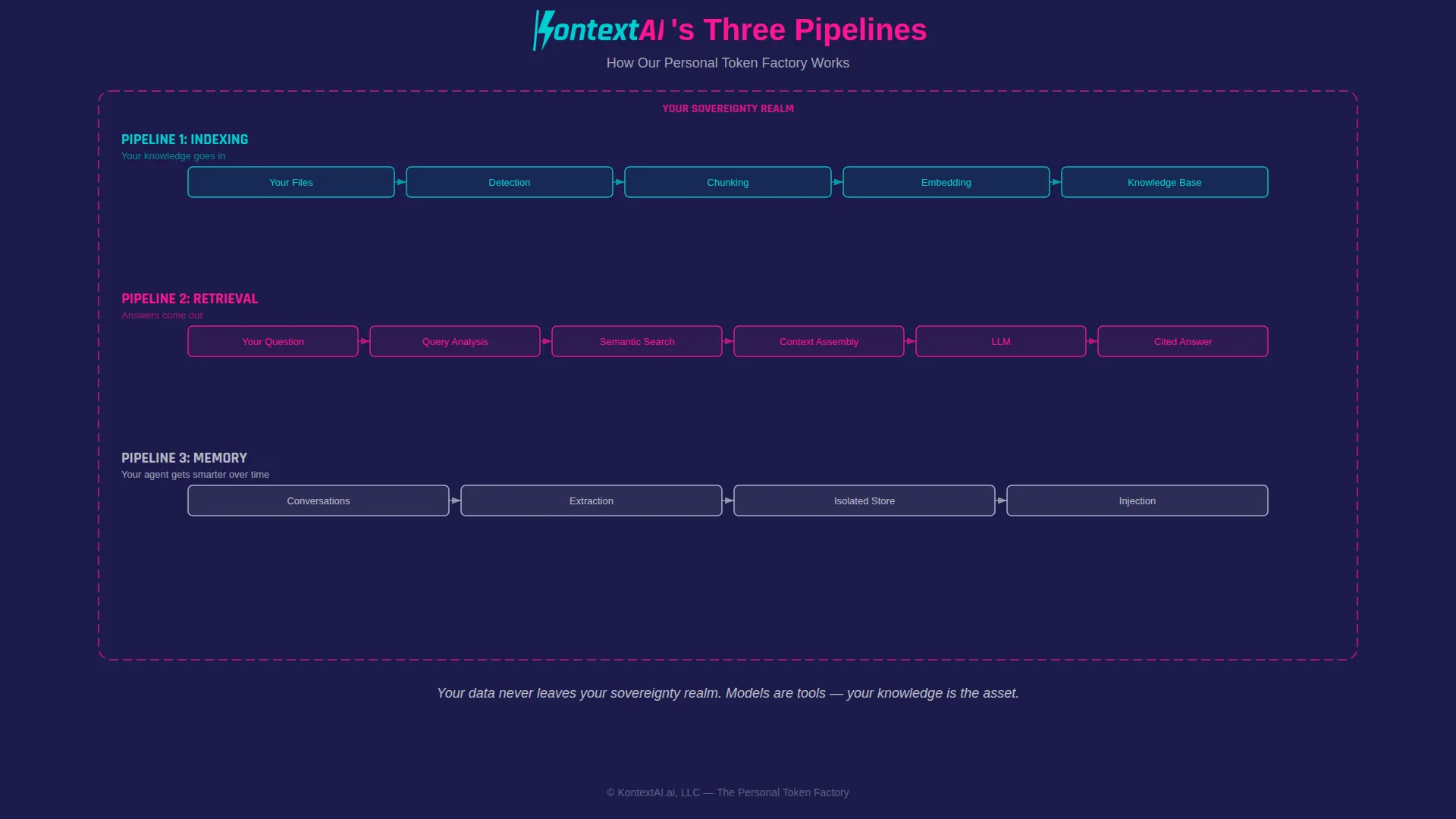
When you upload a file to KontextAI (a book, a transcript, a manual, your own writing), the system breaks it into tokens. It creates embeddings (mathematical representations that capture the meaning of each chunk, allowing the AI to find relevant passages by concept rather than just keywords). It stores them in your own isolated knowledge base, within the sovereignty realm you define. And when you ask a question, your AI agent searches those tokens, finds the ones that matter, and generates an answer grounded in your content.
Your knowledge goes in. Answers come out. And unlike every other AI platform, the factory is yours.
KontextAI starts where the pain is highest: professionals with large, underutilized knowledge bases.
This is what we mean by a personal token factory:
- You upload the raw material. Books, documents, transcripts, notes, in the formats professionals actually use. PDFs, EPUBs, text files, audio transcripts. A consultant uploads ten years of client frameworks. A professor uploads three semesters of lecture recordings. A researcher uploads two hundred published papers.
- The system creates the tokens. Chunking, embedding, indexing: the infrastructure that makes knowledge retrievable. Each document becomes hundreds or thousands of searchable passages (chunks of meaningful text, typically a paragraph or section in length), each indexed and retrievable by concept, not just keyword.
- Your agent retrieves on demand. Ask a question, get an answer sourced from your own content, with numbered citations pointing back to the exact file and section. You can verify every claim.
- Nothing leaves your control. Your content isn’t shared with other users. It isn’t used to train models. It isn’t sold to advertisers. It stays in your knowledge base, within the sovereignty realm you’ve defined, accessible only to you and the agents you build.
No one else can query your agent unless you decide to let them. No one else benefits from your tokens unless you choose to share them. The factory runs for you.
How It Actually Works
Abstract descriptions only go so far. Here are three concrete scenarios:
The consultant. Sarah has spent twelve years at McKinsey and now runs her own practice. She has frameworks for pricing strategy, market entry analysis, and organizational design scattered across 400+ slide decks, 50 memos, and a decade of email threads. She uploads them to a KontextAI agent. Now when a client asks “What’s the standard framework for evaluating a new market entry?”, her agent pulls from her actual frameworks, not generic advice from the internet, and cites the specific deck and slide number.
The professor. Dr. Okafor teaches advanced immunology at a research university. He has three semesters of recorded lectures (transcribed), 15 years of published papers, and a textbook manuscript. His students upload questions at 2 AM. His agent answers from his own lectures, citing “Lecture 7, timestamp 34:12” or “Chapter 4, page 89.” He’s not replaced. He’s extended.
The researcher. Maya studies climate migration patterns. She has 200 papers she’s authored or co-authored, plus 3,000 papers she’s cited over her career. She uploads her own work and the key references. Her agent becomes a queryable version of her research, one that can cross-reference findings across papers, surface contradictions, and generate literature reviews grounded in her actual corpus.
In each case, the knowledge already existed. It was just trapped in the wrong realm, with no agent to serve it.
The Problem at Every Scale
While the vision is universal, the problem is already acute across every scale of organization. An independent consultant has decades of proprietary frameworks (pricing models, negotiation playbooks, industry analyses) trapped in static files that only they can navigate. A mid-size law firm has forty years of case briefs, precedent research, and client memos scattered across shared drives that no associate can efficiently search. A hospital system has clinical protocols, treatment guidelines, and institutional knowledge locked in PDFs that new residents rediscover by trial and error. A university research department has thousands of papers, grant applications, and lab notebooks that represent irreplaceable domain expertise, queryable by no one, including the people who wrote them.
The pattern is identical at every scale. Valuable knowledge exists. It’s trapped in static formats. No infrastructure makes it retrievable on demand. And the current alternative, pasting it into a general-purpose AI, means surrendering sovereignty over the most valuable asset the organization owns. The personal token factory addresses this at the individual level. The enterprise token factory addresses it at the institutional level. The architecture is the same. The sovereignty guarantees are the same. Only the scale changes.
The Nine Tokens
Ribbit’s taxonomy identifies nine distinct token types flowing through the modern economy [1]. Here’s what most people miss: every single one has a personal equivalent that’s currently trapped in static files or dissolved into someone else’s model.
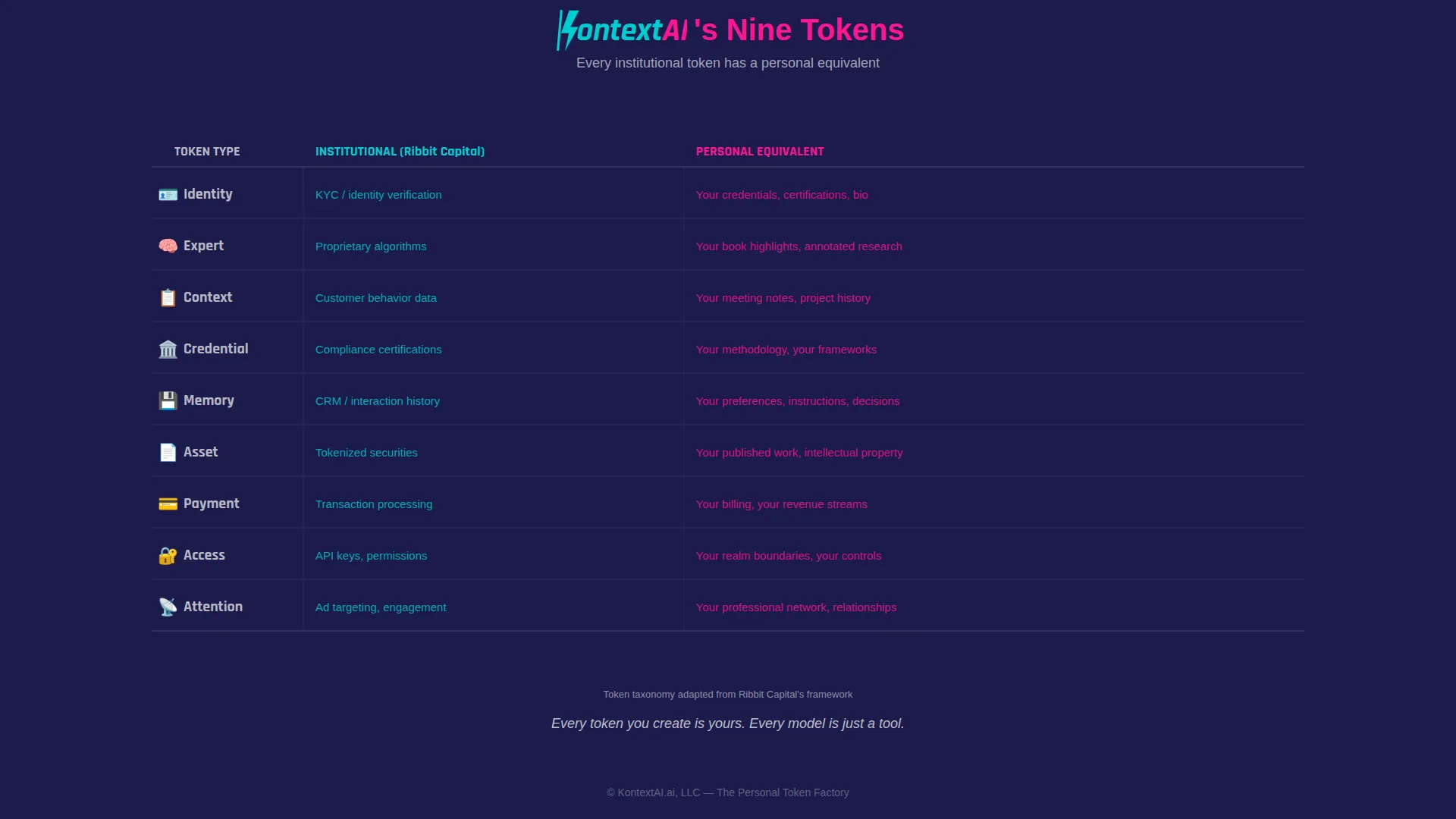
Your highlight from a book is an expert token. Your meeting notes are context tokens. Your methodology for solving problems is a credential token. Your ten years of client deliverables are payment tokens. All of these are currently doing nothing, sitting in folders, buried in email threads, locked in apps that don’t talk to each other.
A personal token factory changes that equation. And sovereignty realms ensure that each token type stays where it belongs.
What Makes This Different
KontextAI is not another AI application. It is the ownership layer between your knowledge and every AI model.
The difference isn’t in the underlying technology. Retrieval-augmented generation is well-understood and widely deployed. The difference is in architectural decisions that most platforms chose not to make.
Ownership by Design
KontextAI processes your input, generates a response, and keeps nothing beyond what you’ve stored in your own knowledge base. We don’t train on your content. We don’t share it across users. We don’t sell it to third parties. The infrastructure exists to make your knowledge retrievable to you, and only to you.
What “ownership” means technically: your files are stored in isolated per-user storage. Vector embeddings are stored with agent-scoped query boundaries; retrieval never crosses agent boundaries, even though the underlying embedding model is shared. Isolation is enforced at retrieval time; the model never sees what it cannot access. This is the same multi-tenant isolation architecture used by enterprise vector databases: per-user scoping at the storage and query layer, with shared infrastructure underneath.
Your knowledge base is exportable at any time in standard, portable formats. And it works in both directions: you can import conversation history and memories from other platforms, including ChatGPT exports, so your existing knowledge comes with you from day one. If you leave, your data leaves with you. We call this portability, the principle that your knowledge should move freely between systems, not be locked into any single platform. Portability is a prerequisite for sovereignty. Without it, ownership is theoretical. There are nuances to portability that matter, and we’ll explore them in depth in Part 2 of this series.
This isn’t a feature toggle. It’s the architecture.
Design Principles. KontextAI is designed with user trust as a structural requirement, not a marketing claim. We do not use dark patterns, infinite scroll, autoplay, or engagement-maximizing algorithms. We do not design features to maximize time-on-platform. The product exists to make your knowledge retrievable, not to keep you scrolling. Retrofitting sovereignty onto a system designed for data aggregation is like adding seatbelts to a motorcycle. We built the car.
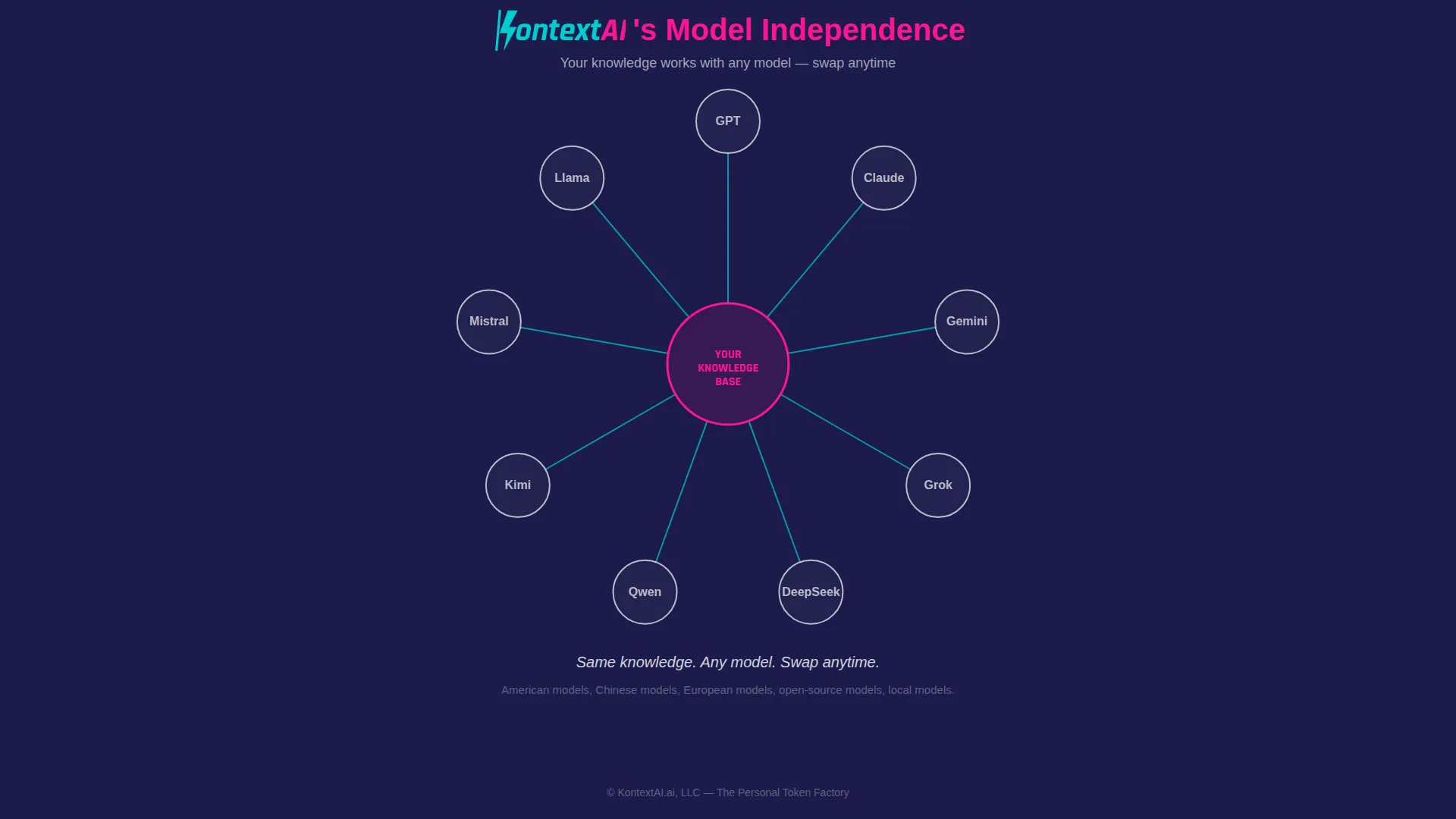
Model Independence
Your knowledge isn’t locked into one company’s AI model. The agent you build works with GPT, Claude, Gemini, Grok, DeepSeek, Qwen, Kimi, Mistral, Llama. American models, Chinese models, European models, open-source models, local models. Swap anytime. The knowledge is yours; the model is a tool. If a better model launches tomorrow, from any country, any company, your knowledge base doesn’t care. It works the same way.
This matters more than most people realize. Model lock-in is the new vendor lock-in. If your knowledge only works inside one platform’s ecosystem, you’re not the owner — you’re the tenant.
Citations as Verification
Every answer your agent generates comes with numbered citations pointing to the exact file, page, and section it used. You can verify every claim. This isn’t a black box — it’s a glass box with receipts.
In a world where AI hallucination is a documented problem (studies show large language models fabricate information in 3-15% of responses depending on domain [18]), citations aren’t a nice-to-have. They’re the difference between a tool you can trust and one you have to double-check.
The citation isn’t just a UI feature. It’s the economic engine that makes AI-generated answers actually useful — because an answer you can’t verify is an answer you can’t act on.
No Training. Ever.
This deserves its own line because it’s the most common question and the most important promise. KontextAI does not train on your data. Not to improve our models. Not to improve our service. Not under any clause buried in a terms of service document. A 2025 Adobe survey of 16,000 professionals found that 69% are concerned about their content being used for AI training without permission, and that concern is well-founded [19]. Your data is used for exactly one purpose: powering your agents’ responses to your queries.
A note on transparency: when your query and retrieved context are sent to a third-party model provider (OpenAI, Anthropic, Google) for inference, that transmission is subject to the provider’s own data policies. As of 2026, major API providers do not train on API data by default, but these are policy commitments, not architectural guarantees. KontextAI’s no-training pledge covers our platform. We encourage users to review the data policies of any model provider they select, and our BYOK option gives you direct control over which provider processes your data.
Every other platform leaves this ambiguous, conditional, or subject to change. We don’t. It’s a design constraint, not a policy decision.
Why This Architecture Survives
The natural question: why won’t the major platforms just add this? Because sovereignty is architecturally incompatible with their business model. Isolated per-user storage, model independence, realm-scoped retrieval, exportable everything: these are design constraints that reduce the platform’s ability to learn from aggregate usage. A company that makes money by understanding patterns across all users has a structural disincentive to build walls between them. Asking OpenAI to build sovereignty realms is like asking a bank to help you hide money under your mattress. They can do it. They won’t. The incentives point the wrong way.
There’s a deeper structural reason. The entire valuation thesis of every major AI company rests on a single premise: more data produces better models. The scaling laws that justify hundred-billion-dollar investments in compute infrastructure depend on an ever-expanding corpus of training signal. Your conversations, your uploaded documents, your usage patterns: these aren’t a byproduct. They’re the raw material the next model is built from. Every sovereignty wall you erect is a wall between their model and the data it needs to improve. A platform whose existence depends on absorbing knowledge will never voluntarily stop absorbing it. The incentive isn’t misaligned. It’s perfectly aligned in the opposite direction.
The major platforms are also the model. OpenAI runs ChatGPT and the GPT model family. Anthropic runs Claude and Claude Code, currently offering Sonnet and Opus. Google runs Gemini. They can’t offer model independence because they ARE the model — their entire business depends on you using their inference, their context window, their ecosystem. KontextAI is model-agnostic by design. Your knowledge base works with any provider. You can switch from GPT to Claude to Gemini to DeepSeek to a local Ollama model without moving a single file. The knowledge layer and the inference layer are decoupled. That’s not a feature. That’s the architecture. And it’s an architecture no model provider will voluntarily build, because decoupling the knowledge from the model removes their lock-in. KontextAI isn’t a front-end for commodity LLMs. It’s the sovereign layer on top of them — and unlike the LLMs themselves, it has no incentive to absorb your knowledge into its own product.
The Implication
If you accept that the context window is the new real estate — the space where relevance is determined, where answers are sourced, where expertise either shows up or doesn’t — and if you accept that different types of knowledge belong in different sovereignty realms with different boundaries, then the question of who owns the tokens becomes the most important question in AI.
The answer, right now, is that almost nobody owns their own tokens. 800 million people a week [13] are producing tokens for platforms that keep the value. And it’s not just individuals. Enterprises pour their most sensitive institutional knowledge (product roadmaps, customer insights, competitive research, compliance frameworks) into AI systems they don’t control. A $214 billion content and knowledge economy [20] is running on infrastructure where the knowledge holders have no sovereignty over their own expertise.
Consider what it means for an enterprise to own its token factory with proper realm boundaries. Every internal process document in the operations realm. Every sales playbook in the revenue realm. Every customer support script in the service realm. Every engineering post-mortem in the technical realm. Tokenized, indexed, and retrievable through AI agents that respect the boundaries between them. Not fed into a third-party model. Not subject to another company’s data retention policy. Not accessible to competitors who happen to use the same platform. Sovereign. Isolated by realm. Theirs.
The AI knowledge management market is projected to reach $51.36 billion by 2030, growing at 46.2% annually [21]. Enterprises are already building token factories. They just don’t call them that, and most of them are building on someone else’s land without realm boundaries.
The personal token factory and the enterprise token factory are the same architecture at different scales. The consultant who uploads ten years of frameworks needs the same sovereignty guarantees as the hospital system that uploads clinical protocols. Isolated storage. Model choice. Export rights. Citation trails. No training. Realm boundaries between knowledge types.
The only difference is the invoice.
Today, KontextAI is a personal tool. You upload your files, you build your agents, you query your knowledge. It’s useful and it’s private. That alone is worth something: a knowledge base that works for you instead of for a platform, with sovereignty realms that keep your different types of knowledge properly separated.
But personal token factories have a property that billboards and search ads never did: they can connect.
That’s Part 2 of this series.
The transition won’t feel dramatic at first. It will look like small decisions: choosing where your knowledge lives, which systems you trust, what you allow to compound. But over time, those decisions determine something much larger: whether your intelligence remains yours, or becomes part of someone else’s system.
In the age of AI, you don’t compete on intelligence — you compete on owned context. And if you don’t own your context, you don’t own your intelligence.
Sources
[1] Ribbit Capital, “Token Letter,” June 2025. Periodic letter published on the Perspectives section of ribbitcap.com. https://ribbitcap.com/knowledge
[2] Liu Liehong, Director of China’s National Data Administration. Remarks at the China Development Forum, March 2026.
[3] Alphabet Q2 2025 earnings call, July 2025. Google reported 980 trillion tokens per month, up from 480 trillion three months earlier. https://abc.xyz/investor/
[4] Jensen Huang, CEO of NVIDIA. Quoted on sovereign AI and national intelligence production, GTC 2024-2026.
[5] David McQuarrie, Chief Commercial Officer, HP. Quoted on sovereign data retention and consumer expectations.
[6] Alan Kay. “Point of view is worth 80 IQ points.” Widely attributed.
[7] McKinsey & Company, “Sovereign AI: Building Ecosystems for Strategic Resilience and Impact,” March 2026. https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/sovereign-ai-building-ecosystems-for-strategic-resilience-and-impact
[8] European Union AI Act, effective August 2026. Penalties up to 35 million euros or 7% of global revenue.
[9] Jake Van Clief, “Environments Over Agents,” arXiv, March 2026. https://arxiv.org/abs/2603.16021
[10] Anthropic Engineering Blog, “Equipping Agents for the Real World with Agent Skills,” 2025. https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
[11] Fierce Network, “NVIDIA GTC: OpenClaw is the new Linux, and every company needs a strategy, says Jensen Huang,” March 2026. https://www.fierce-network.com/broadband/nvidia-gtc-openclaw-new-linux-and-every-company-needs-strategy-says-jensen-huang
[12] CNBC, “Nvidia CEO Jensen Huang says OpenClaw is ‘definitely the next ChatGPT,’” March 2026. https://www.cnbc.com/2026/03/17/nvidia-ceo-jensen-huang-says-openclaw-is-definitely-the-next-chatgpt.html
[13] OpenAI DevDay, November 2025. Sam Altman keynote announcing 800M+ weekly active users.
[14] Hyperscaler AI capital expenditure, 2025. $399 billion, +68% year over year. Compiled from Alphabet, Microsoft, Amazon, and Meta earnings reports.
[15] MarketsandMarkets, “Retrieval-Augmented Generation Market,” 2026. $3.3 billion (2026), projected $9.86 billion by 2030.
[16] Andreessen Horowitz (a16z), “Big Ideas 2026.” Identified unstructured, multimodal data as enterprises’ biggest AI bottleneck.
[17] Apptopia via Fortune, “ChatGPT’s market share is slipping as Google and rivals close the gap,” February 2026. https://fortune.com/2026/02/05/chatgpt-openai-market-share-app-slip-google-rivals-close-the-gap/
[18] Stanford HAI, various studies on LLM hallucination rates, 2024-2026. Reported fabrication rates of 3-15% depending on domain.
[19] Adobe Creators’ Toolkit Report, October 2025, n=16,000. Found 69% of professionals are concerned about AI training on their content without permission.
[20] Goldman Sachs and Grand View Research, 2026. Content and knowledge economy valued at $214 billion.
[21] Business Research Company, “AI Knowledge Management Market,” 2026. Projected $51.36 billion by 2030 at 46.2% CAGR.
KontextAI is a personal AI agent platform. Upload your files, build knowledge agents, and own your context.
Part 2 of the KontextAI Perspective Series publishes Q4 2026.